The early manuscripts at the Library of Alexandria were burned, much of early printing was not saved, and many early films were recycled for their silver content. While the internet’s World Wide Web is unprecedented in spreading the popular voice of millions that would never have been published before, no one recorded these documents and images from one year ago. The history of early materials of each medium is one of loss and eventual partial reconstruction through fragments.
Even though the documents on the internet are the easy documents to collect and archive, the average lifetime of a document is seventy-five days, and then it is gone. While the changing nature of the internet brings a freshness and vitality, it also creates problems for historians and users alike. A visiting professor at MIT, Carl Malamud, wanted to write a book citing some documents that were available only on the internet’s World Wide Web system but was concerned that future readers would get the familiar error message “404 Document Not Found” by the time the book was published. He asked if the internet was “too unreliable” for scholarly citation.
Where libraries serve this role for books and periodicals that are no longer sold or easily accessible, no such equivalent yet exists for digital information. With the rise of the importance of digital information to the running of our society and culture, accompanied by the drop in costs for digital storage and access, these new digital libraries will soon take shape.
The Internet Archive is such a new organization that is collecting the public materials on the internet to construct a digital library. The first step is to preserve the contents of this new medium. This collection will include all publicly accessible World Wide Web pages, the Gopher hierarchy, the Netnews bulletin board system, and downloadable software.
If the example of paper libraries is a guide, this new resource will offer insights into human endeavor and lead to the creation of new services. Never before has this rich a cultural artifact been so easily available for research. Where historians have scattered club newsletters and fliers, physical diaries and letters, from past epochs, the World Wide Web offers a substantial collection that is easy to gather, store, and sift through when compared to its paper antecedents. Furthermore, as the internet becomes a serious publishing system, then these archives and similar ones will also be available to serve documents that are no longer in print.
Where we can read the four-hundred-year-old books printed by Gutenberg, it is often difficult to read a fifteen-year-old computer disk. The Commission on Preservation and Access in Washington, DC, has been researching the thorny problems faced trying to ensure the usability of the digital data over a period of decades. While the Internet Archive will move the data to new media and new operating systems every ten years, this only addresses part of the problem of preservation.
Using the saved files in the future may require conversion to new file formats. Text, images, audio, and video are undergoing changes at different rates. Since the World Wide Web currently has most of its textual and image content in only a few formats, we hope that it will be worth translating in the future, whereas we expect that the short-lived or seldom-used formats will not be worth the future investment. Saving the software to read discarded formats often poses problems of preserving or simulating the machines that they ran on.
The physical security of the data must also be considered. Natural and political forces can destroy the data collected. Political ideologies change over time, making illegal what was once legal. We are looking for partners in other geographic and national locations to provide a robust archive system over time. To give some level of security from commercial forces that might want exclusive access to this archive, the data is donated to a special nonprofit trust for long-term caretaking. This nonprofit organization is endowed with enough money to perform the necessary maintenance on the storage media over the years.
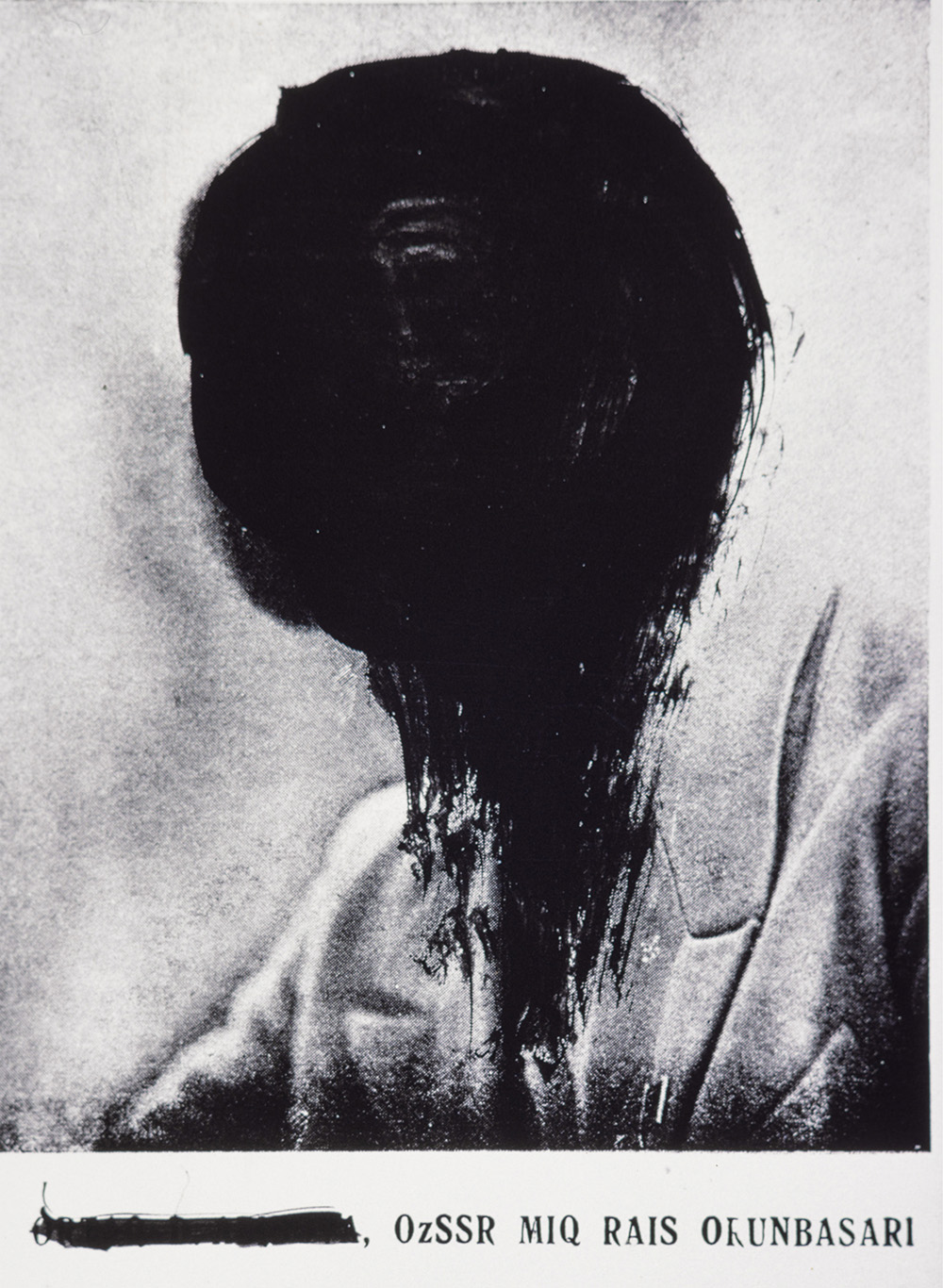
Defaced portrait of Communist Party member Djakhan Abidova, Uzbekistan, c. 1930. Presented to Tate Archive by David King 2016 / © Tate, London / Art Resource, NY.
The World Wide Web is vast, growing rapidly, and filled with transient information. Estimated at fifty million pages, with the average page online for only seventy-five days, the turnover is considerable. Furthermore, the number of pages is reported to be doubling every year. Using the average web-page size of thirty kilobytes (including graphics) brings the current size of the Web to 1.5 terabytes (or million megabytes).
To gather the World Wide Web requires computers specifically programmed to “crawl” the net by downloading a web page, then finding the links to graphics and other pages on it, and then downloading those and continuing the process. This is the technique that the search engines, such as Altavista, use to create their indexes to the World Wide Web. The Internet Archive currently holds six hundred gigabytes of information of all types. In 1997 we will have collected a snapshot of the documents and images.
The information collected by these “crawlers” is not, unfortunately, all the information that can be seen on the internet. Much of the data is restricted by the publisher, or stored in databases that are accessible through the World Wide Web but are not available to the simple crawlers. Other documents might have been inappropriate to collect in the first place, so authors can mark files or sites to indicate that crawlers are not welcome. Thus the collected Web will be able to give a feel of what the Web looked like at a particular time but will not simulate the full online environment.
While the current sizes are large, the internet is continuing to grow rapidly. When it is common to connect one’s home camcorder to the upcoming high-bandwidth internet, it will not be practical to archive it all. At some point we will have to become more select about what data will be of the most value in the future, but currently we can be afford to gather it all.
From “Archiving the Internet.” In 1996 Kahle, a computer engineer and internet entrepreneur, cofounded Alexa Internet—which compiles data on website traffic and user behavior—before selling it to Amazon in 1999. He is also cofounder and digital librarian of the Internet Archive, which now preserves forty-five petabytes of data. “Brewster is one of those guys who has been successful in spite of the fact that he has never been after that kind of success,” wrote computer scientist Kip Parent. “He’s been pushing protocols for the benefit of humanity.”
Back to Issue

